NeRF: Neural Radiance Field 相關閱讀筆記 ft. NeRF-W
這篇文章是學習時整理的一些筆記,讓自己複習時方便,文章內容是閱讀清單之整理
NeRF
Network Design
NeRF,全名Neural Radiance Field,用於生成高質量的三維重建模型並生成新視角影像,在2020 ECCV上被提出,核心關鍵是把一場景用隱式來建模,當網路訓練完成後,可以用來渲染任意視角的場景圖片。 具體成果畫面可以到NeRF計畫網站上看👉NeRF

具體來說,NeRF把所有資訊都交給神經網路來處理:
它把一個連續的場景表示為一個輸入爲5D向量(觀看視角d=(θ,Φ),x=(x,y,z))的函式,輸出是相對應的顏色c=(r,g,b)與密度σ

其中,觀看視角d=(θ,Φ)是由仰角θ和方位角Φ來表示的:
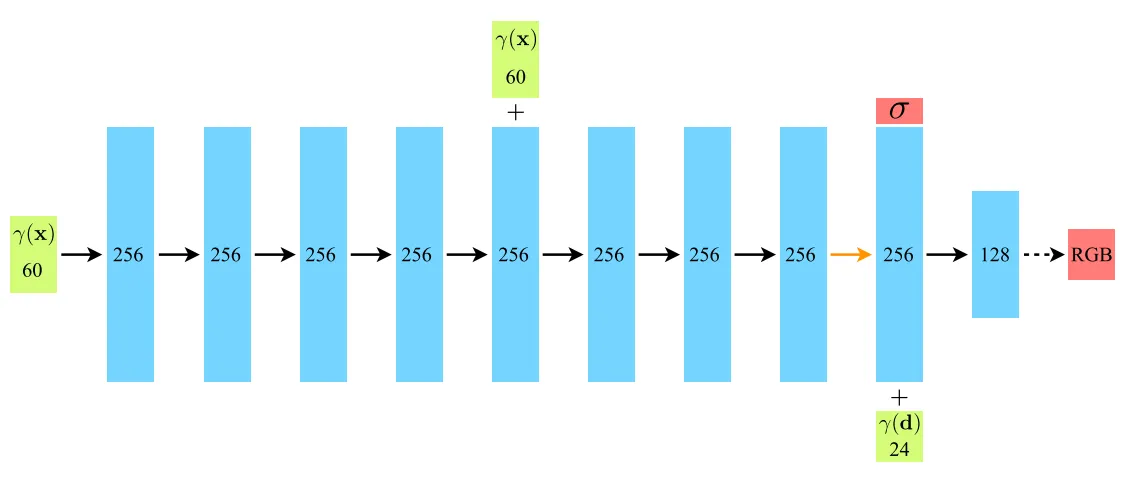
在實作方面,NeRF這個函式是用簡單的MLP來實現的
最基本的網路共10層,前9層維度是256,最後一層維度是128,在第五層有一個skip connection
在第9層時網路會先輸出密度σ,接著再加入觀看視角d再計算在這個角度下的顏色c(因為空間密度只和位置有關,而顏色則與位置和觀察方向有關,不同視角下會有不同的光照效果)
Volume Rendering (ray marching)
從上面NeRF函數得到的是一個3D空間點x=(x,y,z)的顏色和密度訊息,接著可以用體渲染技術來渲染新視角影像。
(當相機(人眼)去對某個3D場景成像時,所得到的畫面上的某一個像素是對應著從相機出發的一條射線上所有的連續空間點,因此我們需要從這條射上的所有點中渲染出最終顏色)
σ(x):一條射線r在經過x處的一個粒子時被終止的機率,而這個機率是可以微分的,可以理解為這個點的不透明度,因為一條射線上的點是連續的,因此這條射線最終成像的顏色可以用積分來算。
一條射線標記為:r(t) = o + td,o是射線原點,d是相機射線角度,因此這條射線的顏色則為:
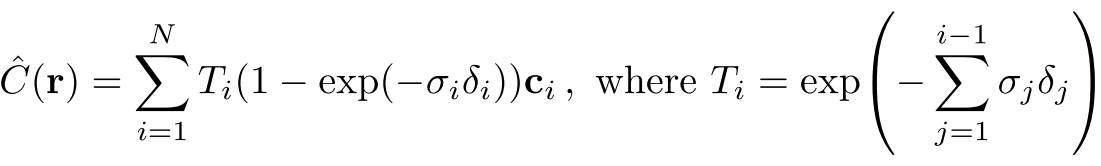
在這裡,T(t)是射線從tn到t這一段路上的累積透明度,可以被理解為tn到t的路上沒有被任何粒子阻擋的機率
從上述解釋可以發現,NeRF將場景視為一個可以穿透的,像雲霧那樣的東西來重建
Some tricks
- position encoding
如果直接將x,d作為網路輸入,則網路的輸出圖像會是相對較模糊的,缺少了高頻資訊,因此會透過position encoding將低維度資料轉成高維度
(用簡單的理解的話,可以理解為在低維度相似的資料,在高維度會距離較遠)
這邊有幾篇對於維度和頻率介紹很好的文章👉图像中的高低频信息简单理解、图像的低频,中频,高频信息含义?
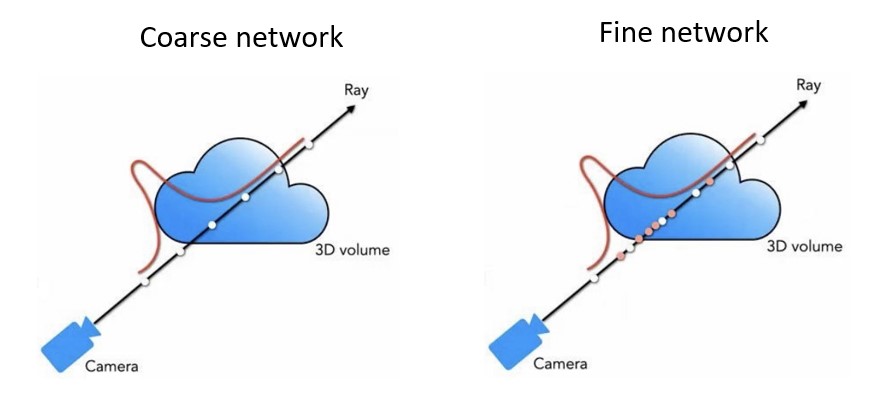
- coarse-to-fine
由於在實際應用中,我們不可能採樣無數個點,因此會透過兩階段採樣策略(粗粒度到精細度)
具體來說,在每一條射線上採樣點計算最終顏色時,先使用一個粗糙網絡預測沿著射線的密度均勻採樣,然後在精緻網絡中在密度較高的區域採樣更多點。
Implementation
接下來這裡才是重點,上面介紹了NeRF的理論,實際上當給定數張視角的照片,要怎麼開始讓網路學習並生成新視角呢?
Camera parameters
我們一共有三個座標體系:
- 世界座標系(World Coordinate): 物理上的三維世界座標
- 相機座標系(Camera Coordinate): 虛擬的三維相機座標
- 圖像座標系(Pixel Coordinate): 二維的圖片座標
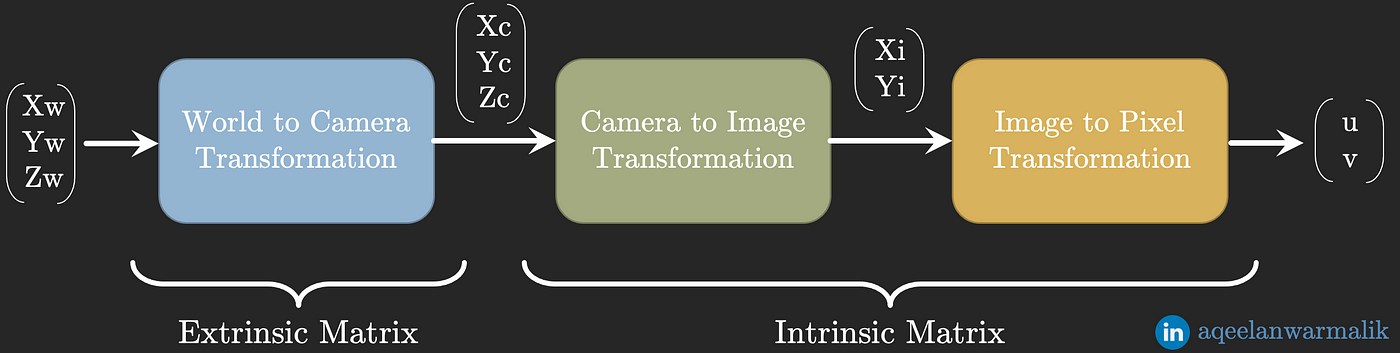
相機座標系中的座標和三維世界中的座標有以下的轉換關係:
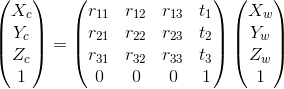
右邊這個矩陣(簡稱為Cex)是一個仿射變換矩陣,也叫相機的外參矩陣,他包含了旋轉訊息(R)和平移訊息(T),用於將世界座標系的某一點P = [xw,yx,zw,1]轉換到相機座標的矩陣,對於NeRF來說,會需要Cex(W2C)和Cex’(逆矩陣,C2W),也就是源位姿(source pose)。
計算機圖學中的矩陣大多默認是列矩陣(column-major matrix),也是OpenCV/OpenGL/NeRF裡使用的形式,4x4的矩陣可以忽略最後一行[0,0,0,1]。
而二維圖片座標系中的座標和相機座標系中的座標有以下的轉換關係:
在這其中,矩陣K是相機的內參矩陣,包含了焦距(focal)(fx, fy),以及圖片中心點的座標(cx, cy)。

對於相同數據集而言,通常相機內參矩陣一般是固定的。因此,最後就可以把整體流程整理成以下公式…

一般來說我們會使用OpenCV的相機座標系風格: Y軸指向下方,X軸指向右方,Z軸指向圖像平面。不同的圖學相機座標系也可能會有所不同,因此會需要轉換。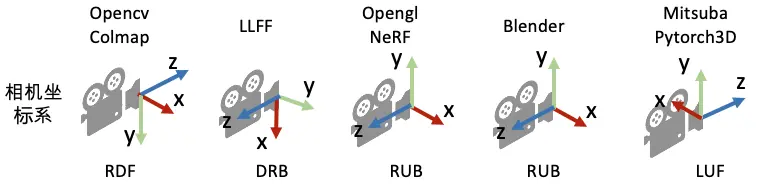
因此colmap採集到的pose在進行訓練之前,需要進行座標系轉換: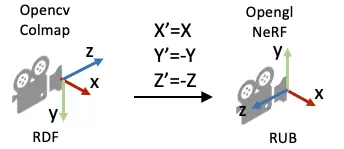
Coordinate transformation
我們已知NeRF的輸入是五維:
而這五維資料是統一在世界座標系下的,也就是相機相對於世界座標系的平移(相機座標系原點在世界座標系下的座標(x,y,z)),以及相機座標系相對於世界座標系下的旋轉(相機座標系的原點對於世界座標系x,z軸的旋轉(θ,φ))。
在NeRF的訓練中,給定一張圖像的一個像素點,構造一個以相機中心為起點、經過像素點的射線r(t) = o + td,需要明確兩點:
- 射線的起點是相機的中心,射線方向是經過成像平面的像素點方向
- NeRF在相機座標系下構建射線,需要通過C2W矩陣將射線變換到世界座標系
![]()
因此,首先要先知道相機中心和像素點在相機座標系中的3D座標:
相機中心座標: 也就是相機座標系的原點, [0,0,0]
像素點的座標: 將像素點的2D圖像座標(i,j)減去圖片中心點座標(cx, cy),而z座標設置為焦距
則可以得到射線方向為(i-cx, j-cy, f),之後只要用C2W矩陣把射線方向變換到世界座標系就可以了:
1 | def get_rays_np(H, W, K, c2w): |
其中,dirs中的y,z軸有多加一個負號是因為先前我們提到的座標系不一樣的原因。
這裡提供一個視覺化工具👉3D Matrix Transform
Dataset
NeRF的訓練資料會保存在json中,舉以下blender樂高挖土機為例:
transforms_XXX.json
1 | { |
待更…(哈
這篇文章寫的很好👉搞懂神经辐射场 Neural Radiance Fields (NeRF)
我就是因為看到這篇文章才開始整理筆記的!
NeRF-W: NeRF in the wild
- 去除不必要的(會變化的)物件
- 場景可隨時間變化
因爲在現實生活中,有些拍的照片的環境會因為光照、時間、人物而有所變化,例如下面這張圖,有時候會有很多觀光客,因此NeRF-W被提出來解決這個問題,來讓神經網路學習哪些是會動的,哪些是不會動的。除此之外,因為場景可能有時候是陰天,有時候是晴天,因此它也可以學習場景如何隨時間變化。

NSFF: Neural Scene Flow Fields
待更…
Reading List
這邊整理了很多很好的學習網址~
NeRF 背景技術
感覺該重新修計算機圖學習了…
- 计算机视觉-相机内参数和外参数
- Ray-Tracing: Generating Camera Rays
- 相机的内参和外参介绍
- 搞懂神经辐射场 Neural Radiance Fields (NeRF)
- Camera Calibration 相機校正
- 【筆記】Camera
- Why do we move the world instead of the camera?
- OpenGL 筆記 - Coordinate System
NeRF 本文
NeRF 延伸系列
- 【AI講壇】NeRF與它的快樂夥伴們 [Neural radiance fields]
- 【AI講壇】NeRF與它的快樂夥伴們2 [Neural radiance fields]
- 【AI講壇】Instant NGP - 地表最快重建技術!
- 【AI講壇】論文介紹 Mip-NeRF360與BlockNeRF [Neural radiance fields]
- 【AI講壇】Depth supervised NeRFs - 用depth強化nerf的方法們 [Neural radiance fields]
Reference
- NeRF Representing Scenes as Neural Radiance Fields for View Synthesis
- NeRF:Representing Scenes as Neural Radiance Fields for View Synthesis
- 图像中的高低频信息简单理解
- 图像的低频,中频,高频信息含义?
- 搞懂神经辐射场 Neural Radiance Fields (NeRF)
- 新视角合成 (Novel View Synthesis) - (1) 任务定义
- nerf 视图与坐标系
- Ray-Tracing: Generating Camera Rays
- NeRF 论文主要点细致介绍


